Embodied systems experience the world as 'a symphony of flows': a combination of many continuous streams of sensory
input coupled to self-motion, interwoven with the motion of external objects. These streams obey smooth,
time-parameterized symmetries, which combine through a precisely structured algebra; yet most neural network world
models ignore this structure and instead repeatedly re-learn the same transformations from data.
In this work, we
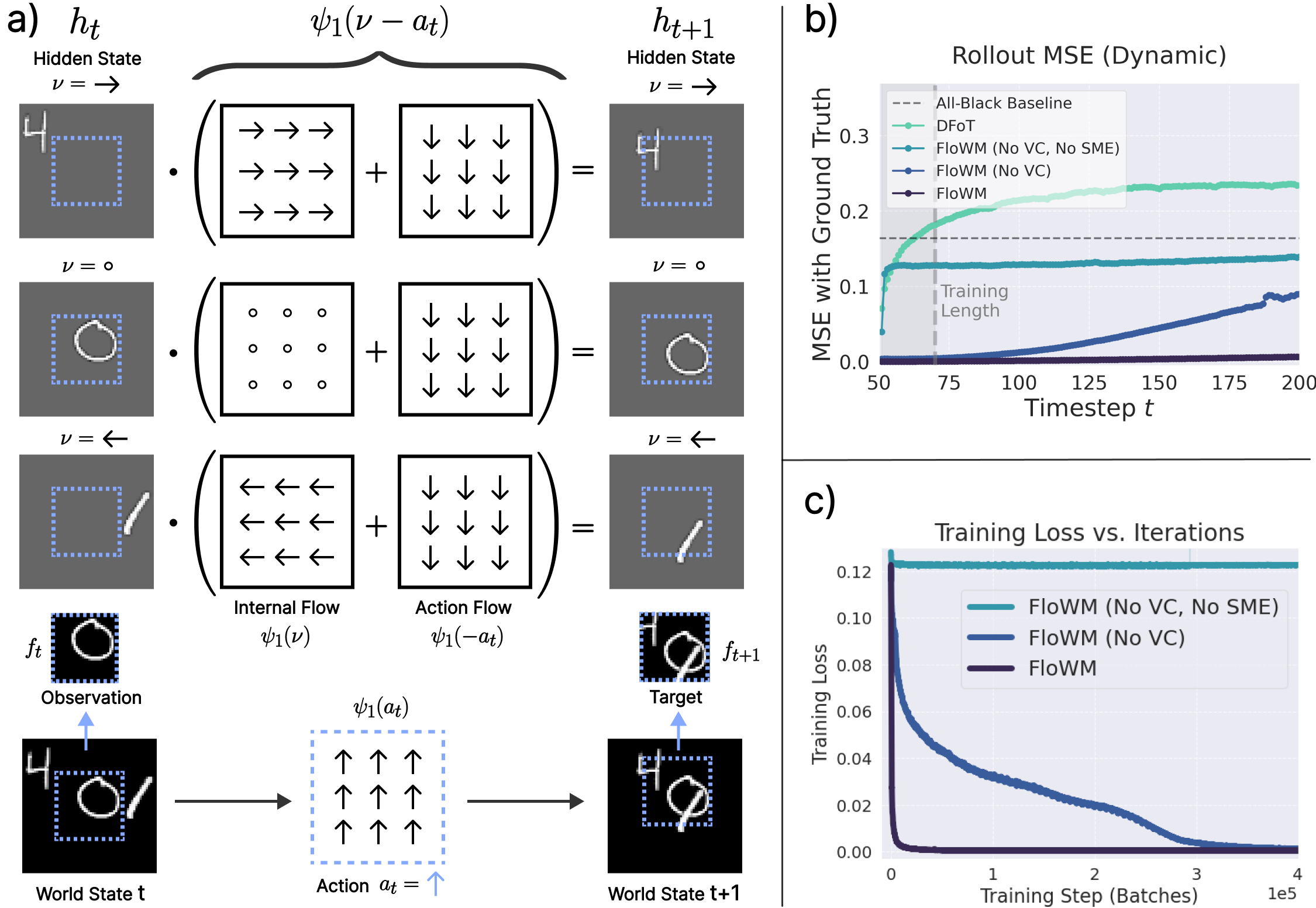
introduce 'Flow Equivariant World Models', a framework in which both self-motion and external object motion are
unified as one-parameter Lie group 'flows'. We leverage this unification to implement group equivariance with respect
to these transformations, thereby sharing model weights over locations and motions, eliminating redundant re-learning,
and providing a stable latent world representation over hundreds of timesteps.
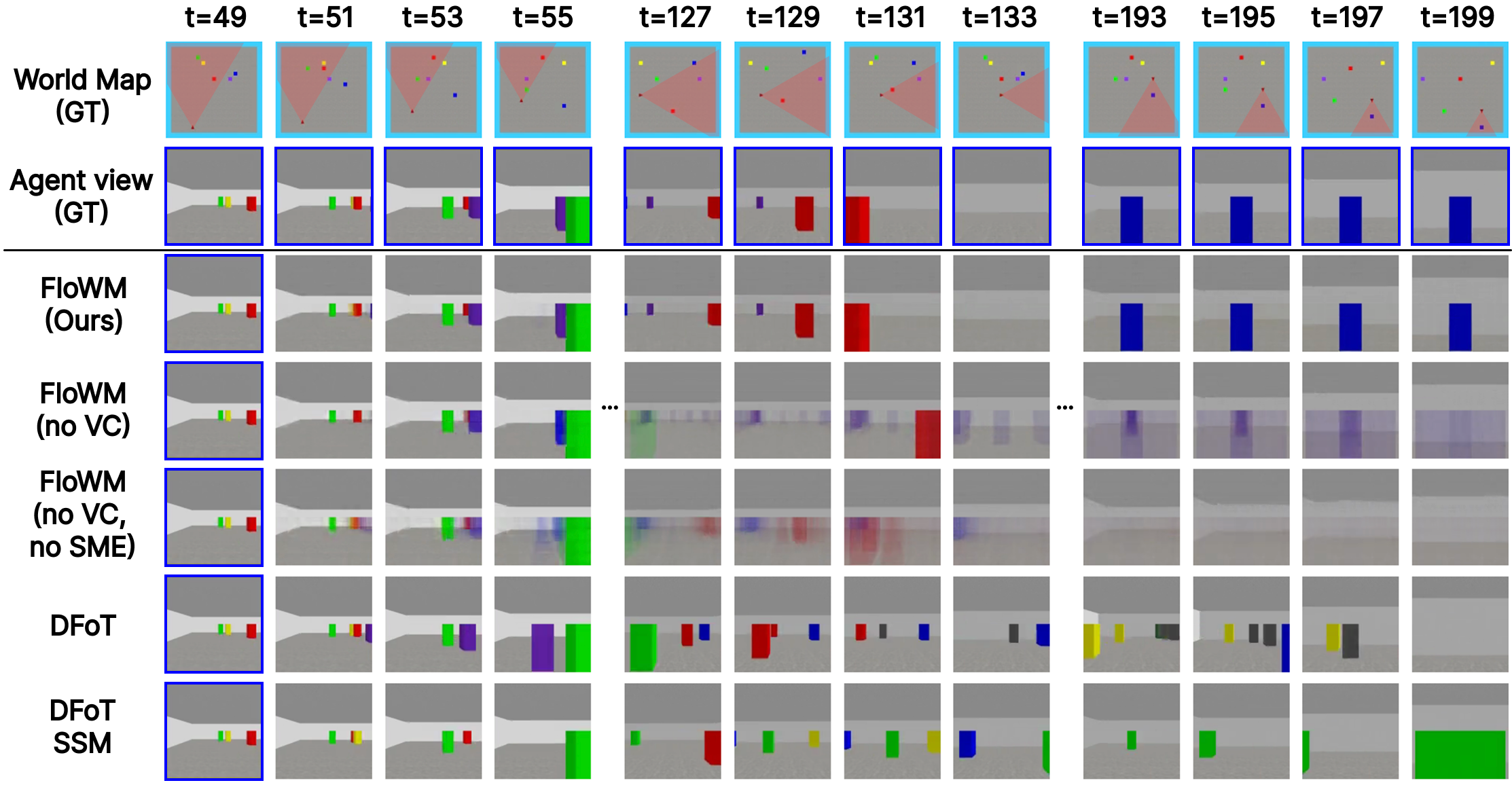
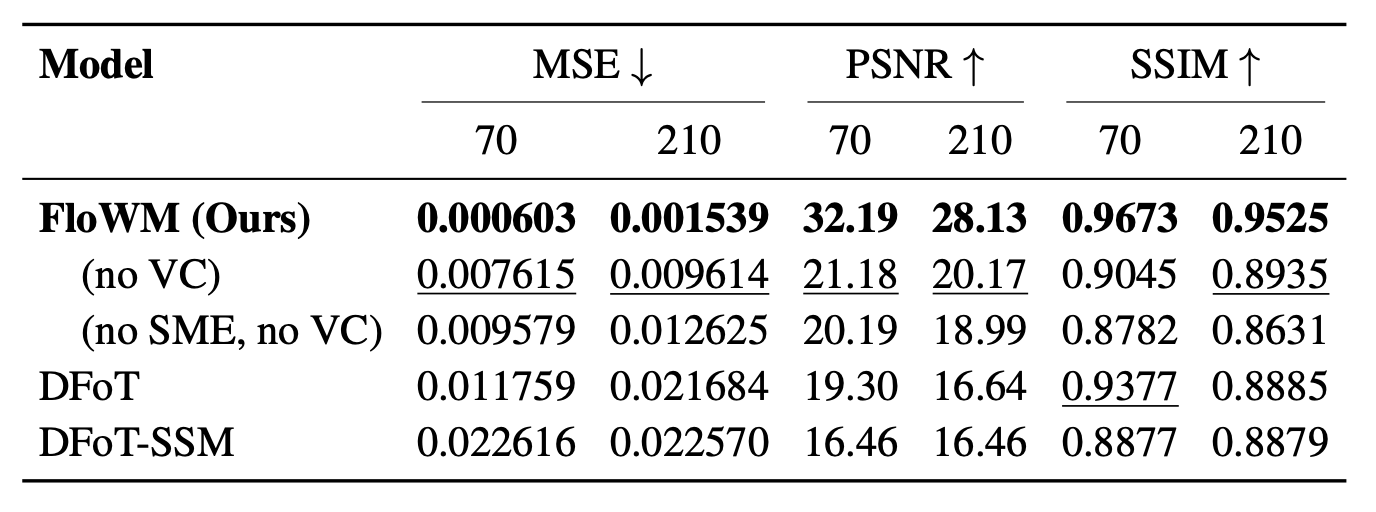
On both 2D and 3D partially observed
world modeling benchmarks, we demonstrate Flow Equivariant World Models significantly outperform comparable
state-of-the-art diffusion-based and memory-augmented world-modeling architectures, training faster and reaching lower
error -- particularly when there are predictable world dynamics outside the agent's current field of view. We show that
flow equivariance is particularly beneficial for long rollouts, generalizing far beyond the training horizon. By
structuring world model representations with respect to internal and external motion, flow equivariance charts a
scalable route to data-efficient, symmetry-guided, embodied intelligence.
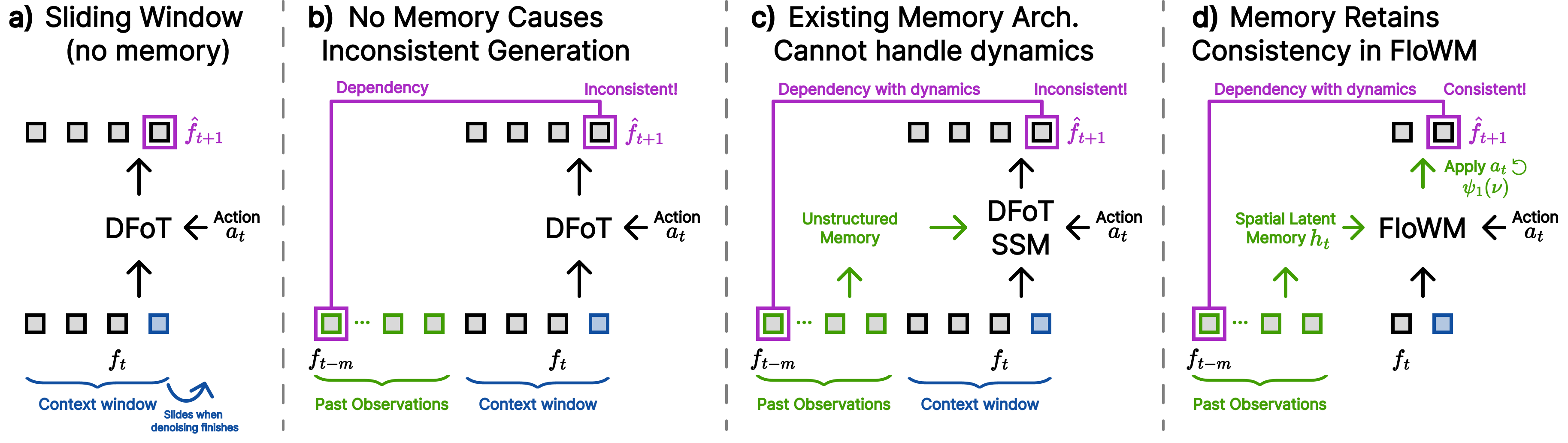
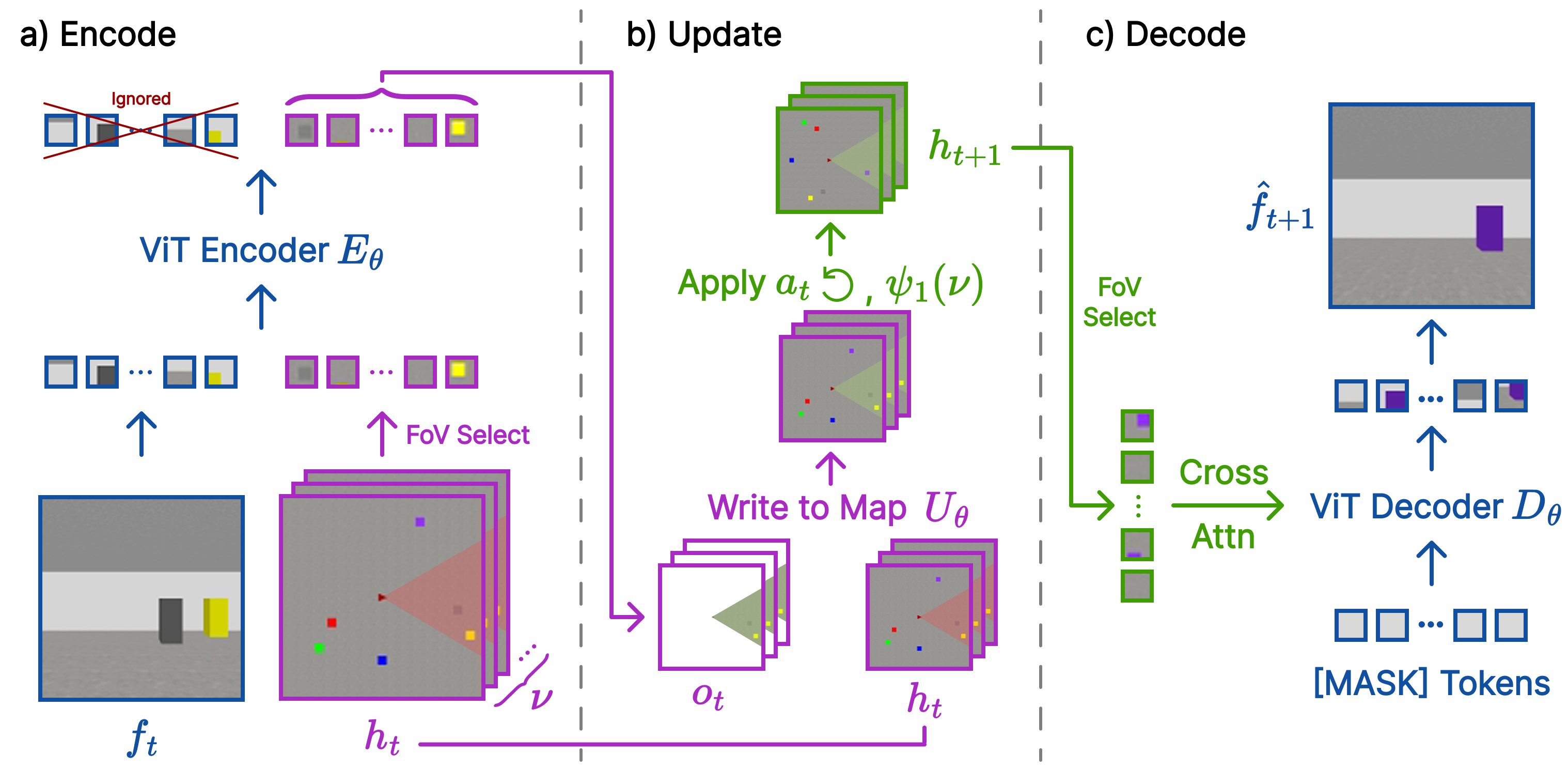
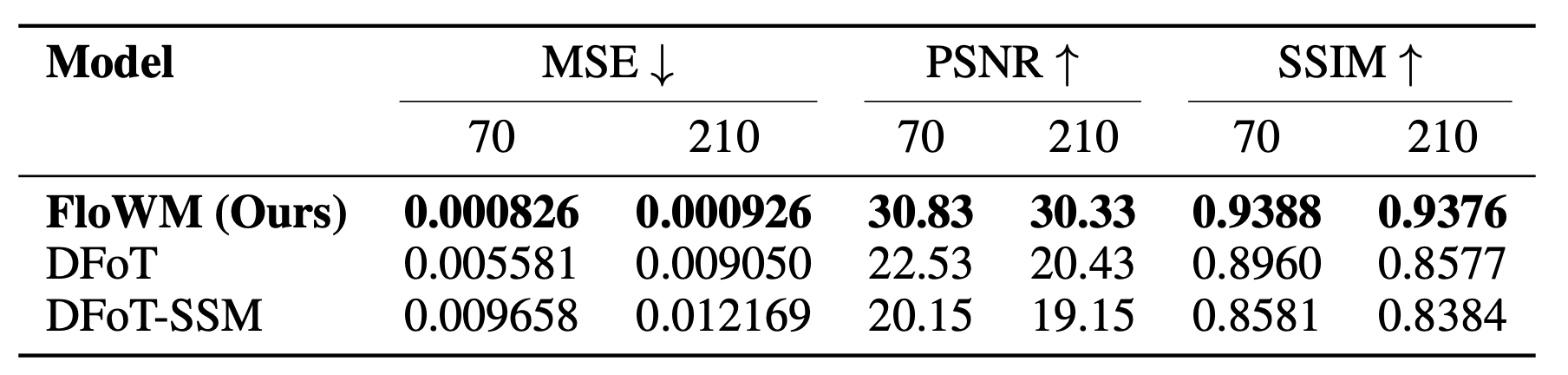
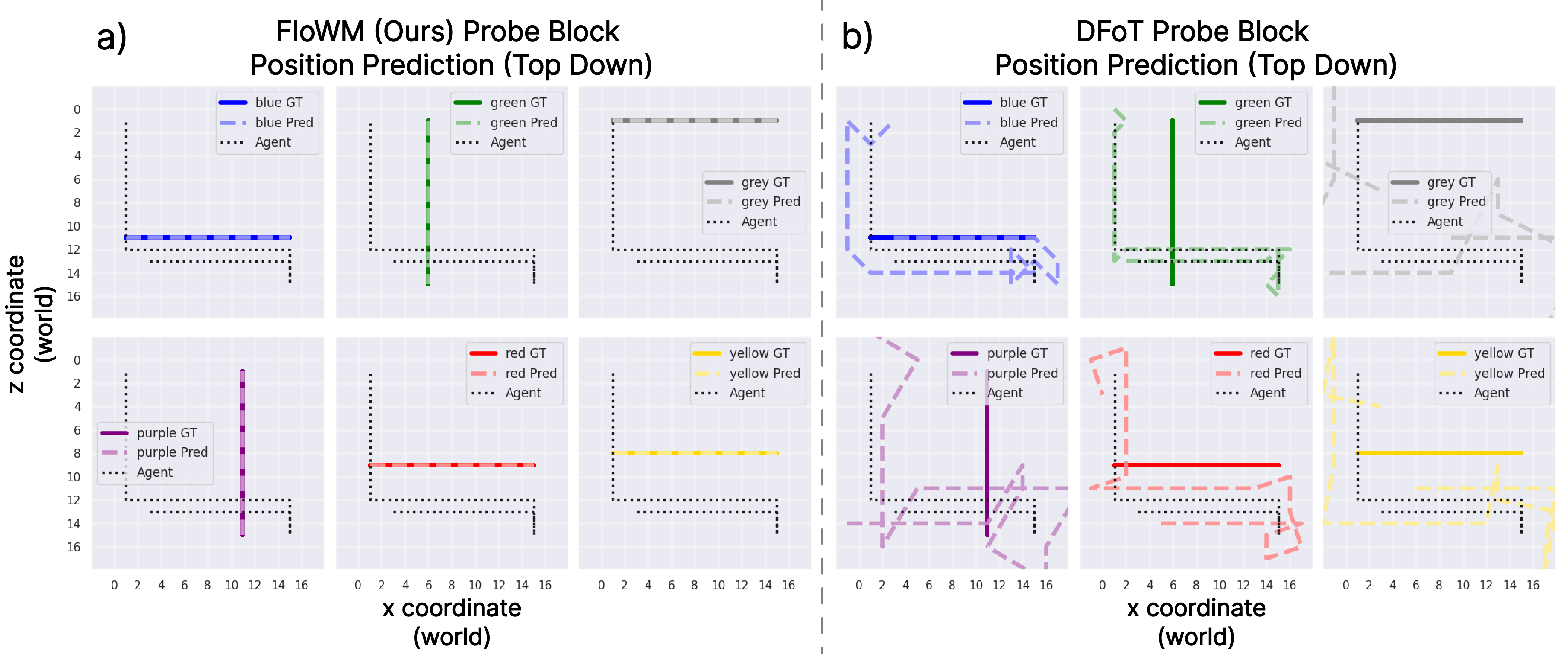
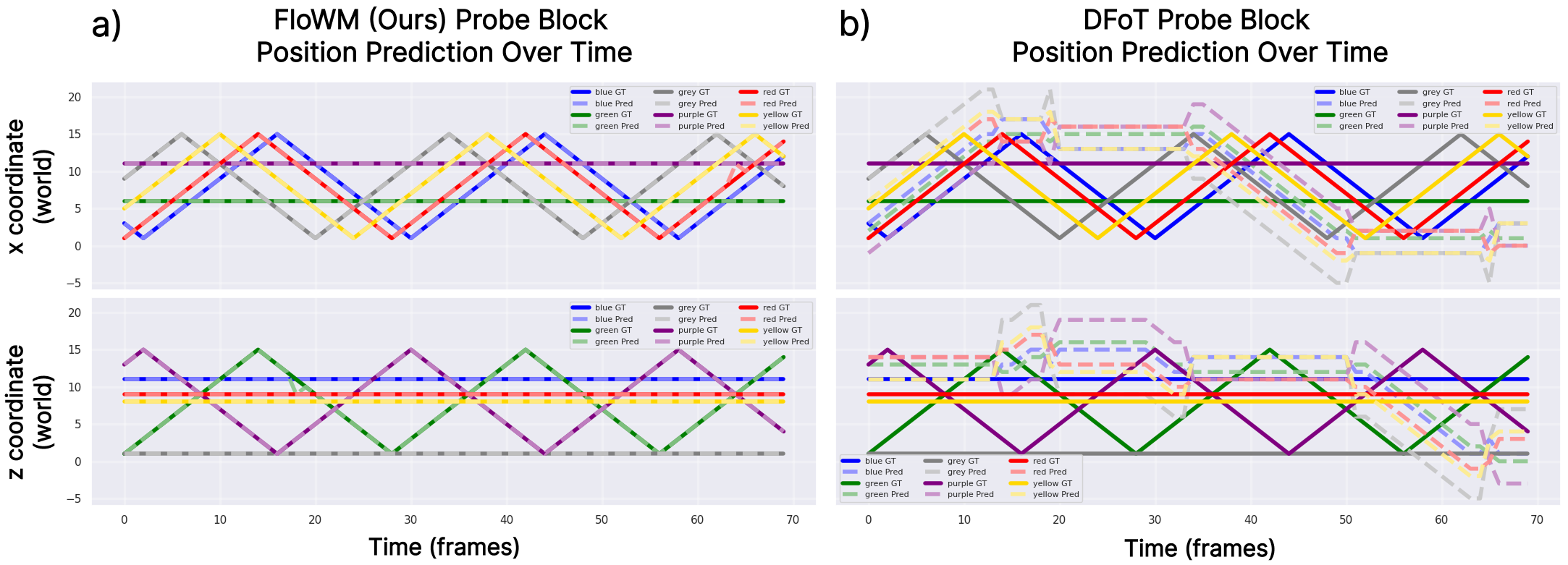
In summary, FloWM is an action-conditioned video world model that can simulate future dynamics within its memory representation
using flow and self-motion equivariance, surpassing prior unstructured video world models on video prediction in
partially observed dynamic settings.
Below, we overview the 3D FloWM model, the 2D FloWM model,
present 3D Blockworld results, and
2D MNIST World results.
 1
Harvard University;
1
Harvard University;
 2
UC San Diego
2
UC San Diego
 3
Carnegie Mellon University
3
Carnegie Mellon University